Hadoop入门概览(二)
一、MapReduce概念
- MapReduce是Hadoop自带的计算框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
- MapReduce指的是Hadoop程序执行的两个计算任务:MapTask和ReduceTask
- MapTask:是将大量的数据处理成一对对键值对数据,并将他们作为output file,输出的kv文件各自有一个shuffle的过程,确保他们各自分区内的数据是有序的。默认按hash值分区
- ReduceTask:拉取MapTask输出的分区文件,做一个简单的shuffle,将不同的MapTask输出的同一个分区下的文件做到有序,然后进行业务逻辑。
二、shuffle机制(非常重要,对于后面的spark和flink的理解有非常重要的作用)
-
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
-
Shuffle目的:使ReduceTask能够处理MapTask处理过的文件。中间会做两次shuffle。
- 第一次shuflle是在map之后,首先做快排,保证map读取到的k值在内存缓冲区中能快速做到有序,然后不断地把内存缓冲区中的文件溢出到本地磁盘文件,最后将这些本地磁盘文件归并成同一个分区的文件。
- 第二次shuffle是在reduce之前,reduceTask节点的机子拉取对应分区的文件到本地,这些分区文件来自不同的mapTask节点,因此要做一个归并排序,保证对应分区的不同mapTask节点的数据能做到有序,随后对这些文件进行业务逻辑处理。
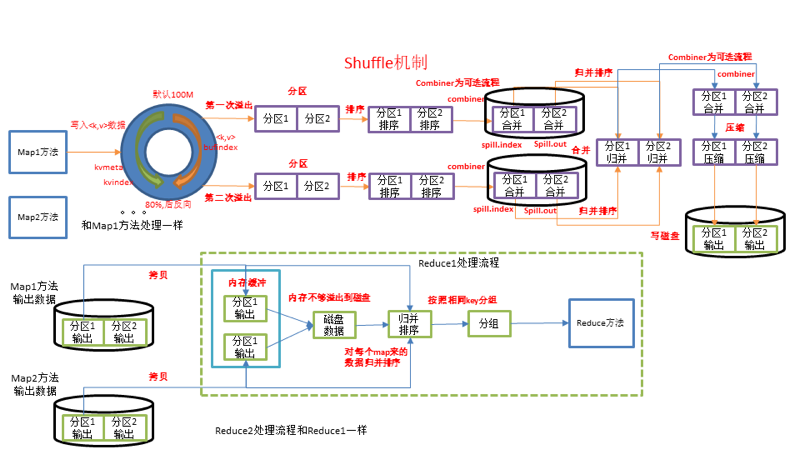
-
结论:
- 内存缓冲区中的内存如果太小,会多次把内存中的文件溢出到本地,造成大量的IO,而IO非常耗费性能。因此增大内存缓冲区的内存或者提高内存缓冲区溢写的比例。由80%扩大到90%
- 可以对溢出的文件做一个统一的merge,一次性进行merge,这里有点批处理的感觉。。。
- 提前对部分数据进行Combine操作,Combine就是Reduce操作,只是Reduce对所有MapTask的分区数据进行处理,而Combine只对自己的MapTask的分区数据处理。
三、MapTask的InputFormat
- 数据切片:是逻辑上的切片,MapReduce输入数据的单位。和HDFS的文件块没有任何关系。每一个切片对应分配一个MapTask并行实例处理。
- FileInputFormat各自的实现类
- TextInputFormat(很重要,后面的spark有他的影子)
- TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量, LongWritable类型。值是这行的内容,不包括任何行终止符(换行符和回车符),Text类型。
- TextInputFormat(很重要,后面的spark有他的影子)
四、压缩方式
-
压缩方式选择时重点考虑:压缩/解压缩速度、压缩率(压缩后存储大小)、压缩后是否可以支持切片。
-
种类
- Gzip压缩
- Gzip压缩
- Lzo压缩
- Snappy压缩
-
这里不做过多阐述,企业一般用Lzo和Snappy居多,并且一般用在hive当中。
- 压缩最重要的目的是能减少IO的数据量,因此mapTask阶段需要设置启用压缩
- 压缩文件还可以减少文件的存储大小,从而能提高HDFS的存储能力
-
参数设置
- io.compression.codecs (在core-site.xml中配置):
- 默认值:无,这个需要在命令行输入hadoop checknative查看
- 阶段:输入压缩
- 建议:Hadoop使用文件扩展名判断是否支持某种编解码器
- mapreduce.map.output.compress(在mapred-site.xml中配置):
- 默认值:无,这个需要在命令行输入hadoop checknative查看
- 阶段:输入压缩
- 建议:Hadoop使用文件扩展名判断是否支持某种编解码器
- mapreduce.map.output.compress.codec(在mapred-site.xml中配置):
- 默认值:org.apache.hadoop.io.compress.DefaultCodec
- 阶段:mapper输出
- 建议:企业多使用LZO或Snappy编解码器在此阶段压缩数据
- mapreduce.output.fileoutputformat.compress(在mapred-site.xml中配置):
- 默认值:false
- 阶段: reducer输出
- 建议:这个参数设为true启用压缩
- mapreduce.output.fileoutputformat.compress.codec(在mapred-site.xml中配置):
- 默认值:org.apache.hadoop.io.compress.DefaultCodec
- 阶段:reducer输出
- 建议:使用标准工具或者编解码器,如gzip和bzip2
- io.compression.codecs (在core-site.xml中配置):